Efficient Querying: Finding Maximum Values for Each Distinct Value in a Column
A high-performance alternative to subqueries for solving a tricky query problem.


The following table is a list of famous quotes by Seinfeld characters and (in some cases*) the episode in which they first appeared.
*The sample data was generated by ChatGPT and is only partially accurate (some quotes go to different episodes). That said, the accuracy of the sample data is not relevant to this article, so I'm not going to drive myself any crazier trying to sort it out...so much for ChatGPT saving me time [sigh]
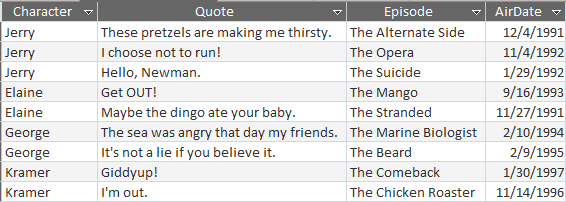
Let's say we want to show the first famous quote for each character based on the episode's air date. In other words, we want to get to this output:

Some Stuff that Doesn't Work
Your initial impulse might be to use a GROUP BY query with a MIN function on the AirDate field.
But, then, what do you do with the Quote and Episode fields?
GROUP BY Character, Quote, Episode, MIN(AirDate)
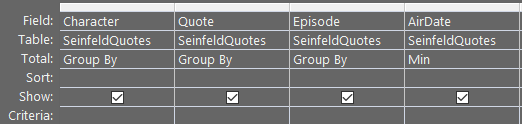
Here's what that looks like:
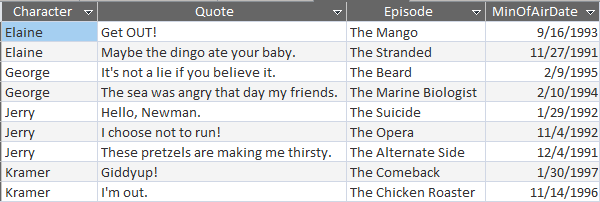
That's no good, because it just returns all the original records. If there were any duplicates of Character-Quote-Episode then it would combine those records and show the minimum AirDate of the group. In any case, it's not what we want.
GROUP BY Character, MIN(AirDate)
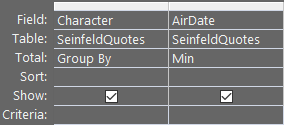
Which looks like this:
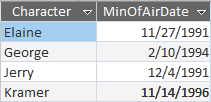
Dropping the GROUP BY on the Quote and Episode columns gets us down to one record per character, but now we've lost the Quote and Episode column data. Still not what we want.
GROUP BY Character, MIN Quote, Episode, AirDate
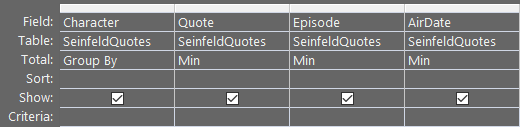
Which gives us this:

This one might be the most dangerous. It looks at first glance like exactly what we want. But if we compare the above output to our expected output from above, we realize that some of the information is wrong.
For example, "The Beard" is not the first of George's listed episodes based on air date. Rather, "The Beard" simply comes before "The Marine Biologist" in alphabetical order. The query is returning the minimum value for each field grouped by Character.
Stepping back and looking at this it is easy to see the mistake.
But if you're not paying close attention during development, it's easy for something like this to slip through the cracks. This is especially true when you are working with data that is outside of your domain knowledge. For example, if you have never seen the show Seinfeld, you would never notice if a catch-phrase got attributed to the wrong character.
Working Approaches
Both of the following approaches will work, but one will perform better than the other.
The SubQuery Approach
Probably the simplest approach to understand is the subquery approach.
For this approach, we start with our GROUP BY Character, MIN(AirDate) query. For simplicity, we'll save that to a query named MinAirDateSubQry. We will then JOIN from our main table to this "sub"-query.
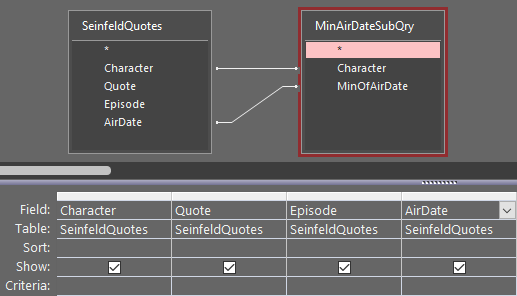
This one works:

Unfortunately, subqueries do not generally perform well. Let's look at an alternative.
The Bill Karwin Approach
I prefer to use Bill Karwin's technique for this situation:
I see many people use subqueries or else window functions to do this, but I often do this kind of query without subqueries in the following way. It uses plain, standard SQL so it should work in any brand of RDBMS.
SELECT t1.*
FROM mytable t1
LEFT OUTER JOIN mytable t2
ON (t1.UserId = t2.UserId AND t1."Date" < t2."Date")
WHERE t2.UserId IS NULL;
In other words: fetch the row fromt1where no other row exists with the sameUserIdand a greater Date.
Microsoft Access Demo
Let's see what that would look like in Access using this table as our sample:
SELECT t1.*
FROM SeinfeldQuotes t1
LEFT OUTER JOIN SeinfeldQuotes t2
ON t1.Character = t2.Character AND ((t1.AirDate > t2.AirDate)
OR (t1.AirDate = t2.AirDate AND t1.Quote < t2.Quote))
WHERE t2.Character IS NULL;One important thing to note is that you cannot use the SQL Design View when editing this type of join. If you do, you will get the following error message:
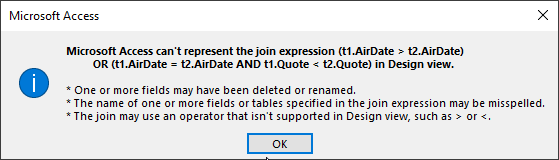
Don't worry! You're not doing anything wrong. Access is just telling you that it can't use graphical lines to model the relationship between the two tables.
It's actually two copies of the same table, but that's not why the join can't be represented. It can't be represented because it relies on an inequality operator (<) rather than an equal sign (=).
Note that in our sample SQL we use the alphabetical order of the Quotes as a tie-breaker if two records share an Air Date. In a real table, I would generally fall back on a unique value (like the table's primary key) as the tie-breaker instead of some random text field which could also easily have duplicates.
External sources
