Get Max Row by Group with ChatGPT
This ChatGPT prompt lets you easily implement Bill Karwin's clever LEFT JOIN solution to a common data selection problem in SQL.

A common but vexing problem is trying to return the max row of data by group in a database table.
For example, consider an Invoice table with the following fields:
- InvoiceID: autonumber primary key
- CustomerID: foreign key to the Customer table
- InvDescription: a description of the invoice
- CreatedAt: date and time the Invoice record was created
- SentOn: date the invoice was sent to the customer
Let's say you want to run a SELECT query that returns the InvoiceID and description for each customer's most recent invoice. For this example, let's define "most recent invoice" using the following ORDER BY clause:
ORDER BY SentOn DESC,
CreatedAt DESC,
InvoiceID DESCNote that the final column in your ORDER BY should be a unique column to avoid any possibility of duplicates. Personally, I always use my table's Autonumber primary key for this purpose.
I covered this problem in a previous article, which included a link to Bill Karwin's Stack Overflow answer which uses an elegant LEFT JOIN to produce an answer that's both very efficient and very portable (many other solutions use proprietary database features like RANK() or CTE's that do not work in Access).
The problem with Bill Karwin's answer is it's a bit counterintuitive. It always takes me a few minutes to wrap my head around what's happening and how I need to translate his answer to fit the specifics of my scenario.
To address that, I wrote the following ChatGPT prompt which leverages Bill Karwin's technique to great effect:
The Prompt
- Copy and paste the prompt below into ChatGPT.
- Enter your Table Name as indicated.
- Enter the Column(s) to Return as indicated.
- Enter the Column(s) to Group By as indicated.
- Enter the Column(s) to Sort By as indicated. Be sure to include
DESCas needed, and make sure the last column listed is unique to avoid duplicates. - Submit the completed prompt.
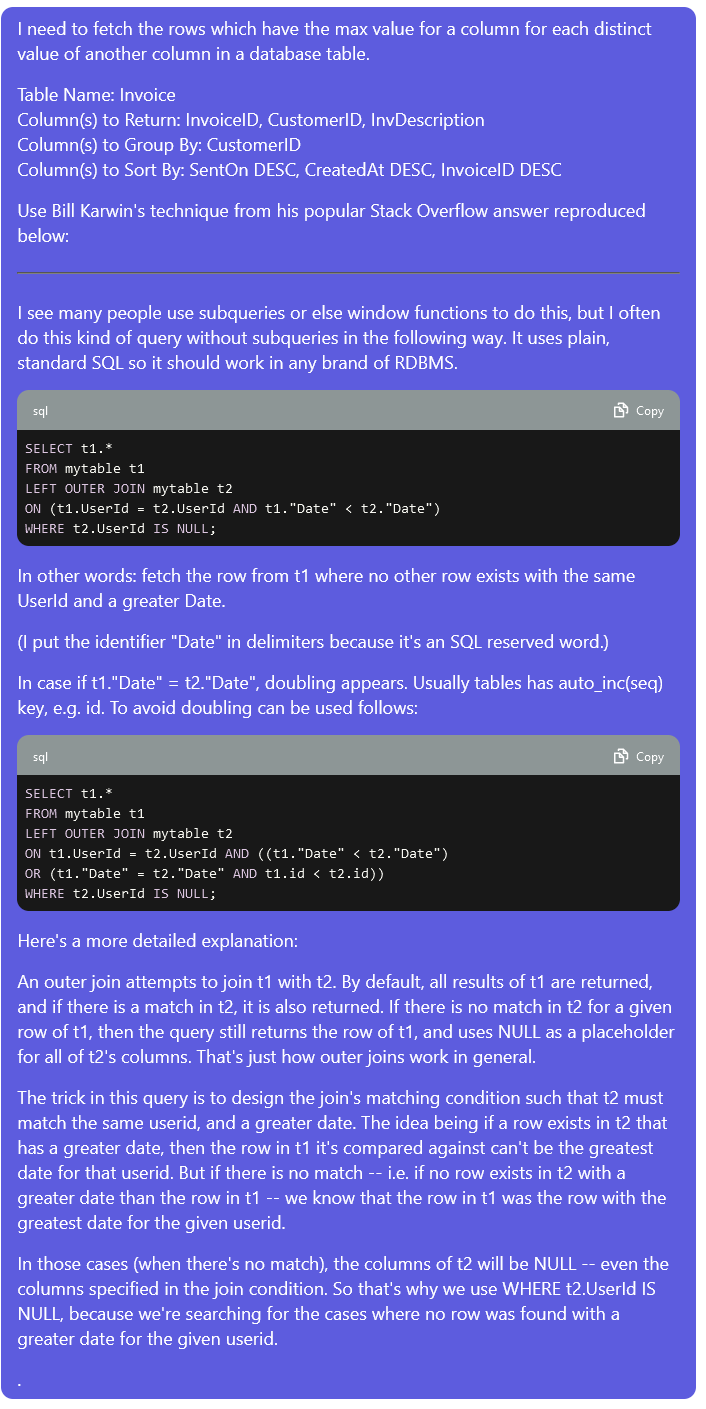
I need to fetch the rows which have the max value for a column for each distinct value of another column in a database table.
Table Name:
Column(s) to Return:
Column(s) to Group By:
Column(s) to Sort By:
Use Bill Karwin's technique from his popular Stack Overflow answer reproduced below:
----------
I see many people use subqueries or else window functions to do this, but I often do this kind of query without subqueries in the following way. It uses plain, standard SQL so it should work in any brand of RDBMS.
```sql
SELECT t1.*
FROM mytable t1
LEFT OUTER JOIN mytable t2
ON (t1.UserId = t2.UserId AND t1."Date" < t2."Date")
WHERE t2.UserId IS NULL;
```
In other words: fetch the row from t1 where no other row exists with the same UserId and a greater Date.
(I put the identifier "Date" in delimiters because it's an SQL reserved word.)
In case if t1."Date" = t2."Date", doubling appears. Usually tables has auto_inc(seq) key, e.g. id. To avoid doubling can be used follows:
```sql
SELECT t1.*
FROM mytable t1
LEFT OUTER JOIN mytable t2
ON t1.UserId = t2.UserId AND ((t1."Date" < t2."Date")
OR (t1."Date" = t2."Date" AND t1.id < t2.id))
WHERE t2.UserId IS NULL;
```
Here's a more detailed explanation:
An outer join attempts to join t1 with t2. By default, all results of t1 are returned, and if there is a match in t2, it is also returned. If there is no match in t2 for a given row of t1, then the query still returns the row of t1, and uses NULL as a placeholder for all of t2's columns. That's just how outer joins work in general.
The trick in this query is to design the join's matching condition such that t2 must match the same userid, and a greater date. The idea being if a row exists in t2 that has a greater date, then the row in t1 it's compared against can't be the greatest date for that userid. But if there is no match -- i.e. if no row exists in t2 with a greater date than the row in t1 -- we know that the row in t1 was the row with the greatest date for the given userid.
In those cases (when there's no match), the columns of t2 will be NULL -- even the columns specified in the join condition. So that's why we use WHERE t2.UserId IS NULL, because we're searching for the cases where no row was found with a greater date for the given userid.
.
Sample Usage
Here's what it looks like using Poe.com with ChatGPT-4 and our example table from above:
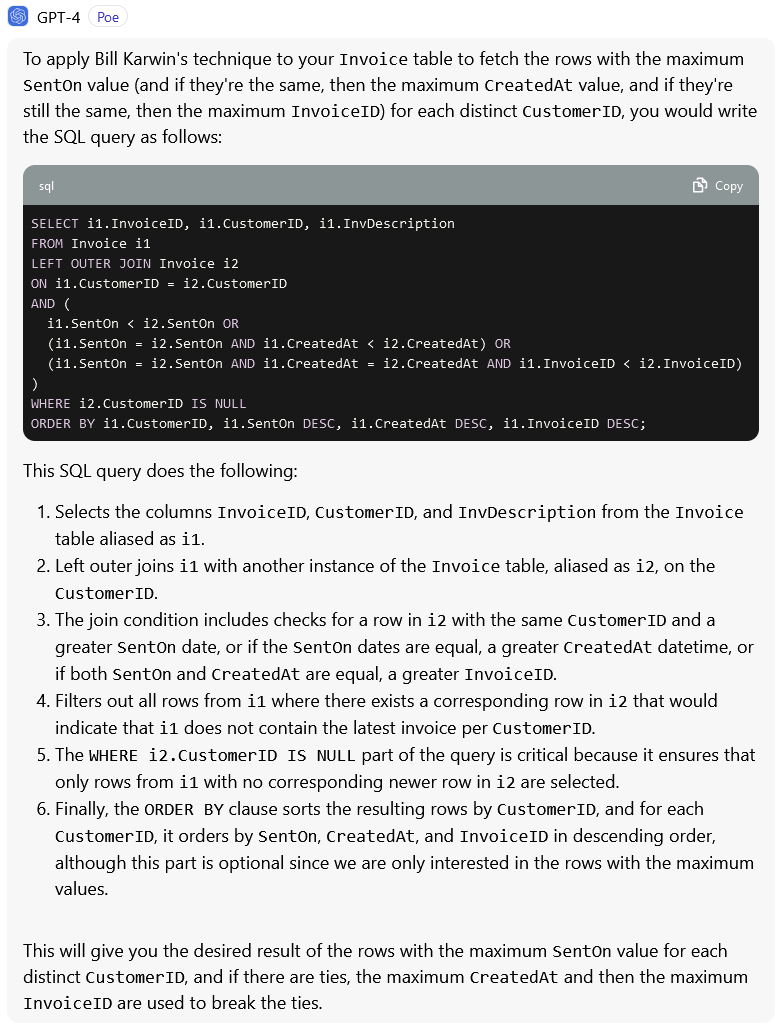
Happy prompting!
References
 Mike Wolfe
Mike Wolfe
