DISTINCT vs. GROUP BY: Microsoft Access Speed Test
The GROUP BY and DISTINCT clauses can both be used to generate identical results. But which one is faster in Access? And--more importantly--why?


In certain situations, the DISTINCT and GROUP BY clauses can be used to generate identical results–but one is consistently faster than the other.
I've been doing a lot of research for my upcoming talk on Troubleshooting Query Performance. As part of that research, I came across the following post by Access guru Colin Riddington:

Colin was responding to a request from user @CJ_London:
We often see OP's using aggregate queries without any aggregation rather than SELECT DISTINCT - do you have an example to compare a SELECT DISTINCT v GROUP BY with perhaps a criteria or two?
Colin was intrigued, so he devised a speed test to compare the two. Before releasing the results, though, he asked for people to predict which clause would win. Colin's gut feeling–which matched my own and most of the respondents–was that the SELECT DISTINCT clause would be faster. It turned out the opposite was true.
GROUP BY was consistently faster than SELECT DISTINCT.
Read on to learn why.
Reproducing the Results
Before going too far, I wanted to run the test on my computer to see if I would get the same results.
After running the test several times, I found that GROUP BY was consistently about 5 - 10% faster than SELECT DISTINCT:

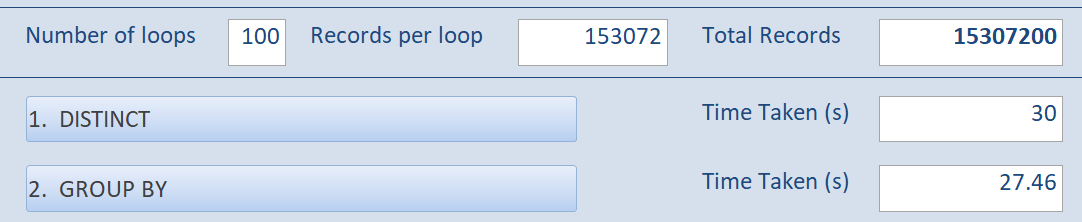


The only test that did not bear this out was when I ran each query only once. I did this as part of my analysis which I will get to later in the article. In fact, when I originally published this article, the final screenshot above was the only one that I included–thus undermining my entire set of findings.
[Tip of the hat to Karl Donaubauer, who notified me privately...and rather diplomatically...that I had just made an ass of myself by writing 1,000+ words about why GROUP BY was faster than DISTINCT when the only proof I posted showed the opposite.]
And that is why you always run performance tests many times–to reduce the impact of external variations during the test (such as other applications temporarily using the processor).
Why is GROUP BY faster than SELECT DISTINCT?
Colin posted the JetShowPlan showplan.out files for the two queries he tested:
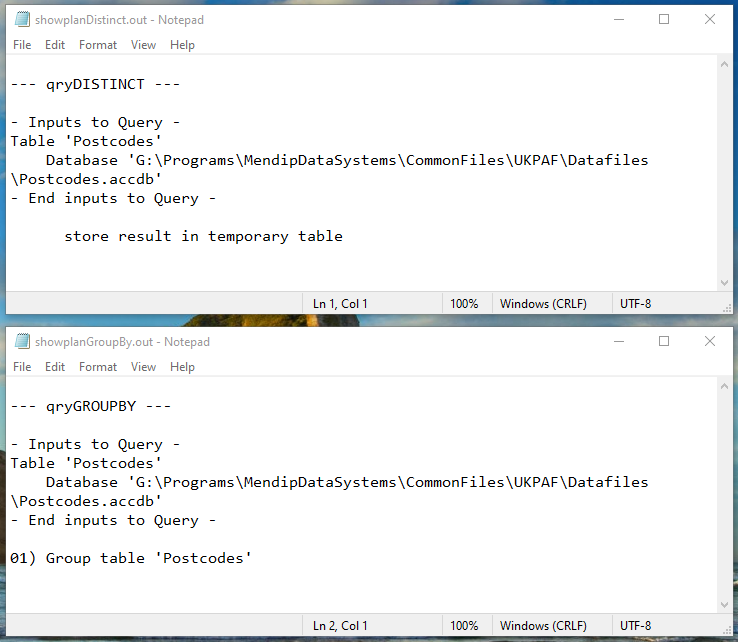
Colin noted that the results were "almost identical."
The one key difference was in the final line of each output.
- SELECT DISTINCT:
store result in temporary table - GROUP BY:
01) Group table 'Postcodes'
Colin concluded his analysis with this final observation:
I'm also surprised by the result & I don't have an explanation for it other than the evidence from JET ShowPlan.
Testing Colin's Theory
Luckily for me, Colin uploaded his testing database, so it was easy for me to pick up where he left off.
If I have seen further it is by standing on the shoulders of giants.
- Sir Isaac Newton
Based on Colin's consistent results, I hypothesized that the difference in the two results was likely based on the fact that the slower clause was writing its results to a "temporary table" while the faster one was not. But how could I put that to the test?
ProcMon to the Rescue
I broke out my trusty friend, Process Monitor, and set up the following filter:
- INCLUDE: Process Name is msaccess.exe
- INCLUDE: Operation is WriteFile

I then ran each of Colin's tests with a single loop to minimize the procmon outputs. Minimizing the results still produced a lot of data (such is the nature of procmon). However, I found the results quite compelling (if a bit difficult to decipher for the uninitiated):
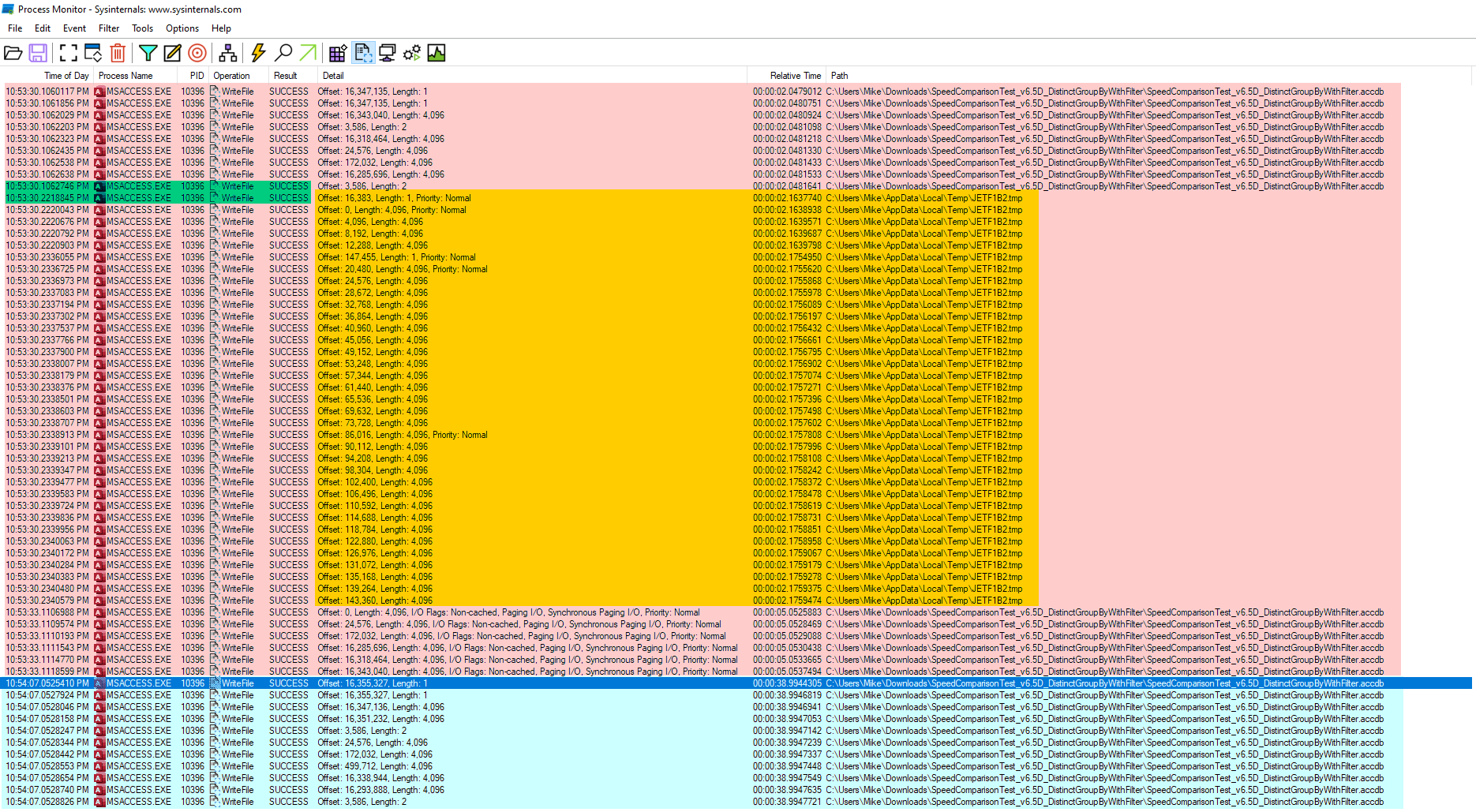
Deciphering the ProcMon Results
I added coloring to the above screenshot to highlight a few key sections:
- Pink: SELECT DISTINCT clause (
store result in temporary table) - Blue: GROUP BY clause (
01) Group table 'Postcodes') - Gold: the temporary file created to hold the "temporary table"
- Green: the 0.1 second delay immediately prior to the first WriteFile operation on the temporary file
The gold and green sections could use a bit more detail. Let's discuss those further now.
Gold: The Temporary File
One of the things I love about ProcMon is getting to see how the sausage is made at the lowest levels of the operating system.
These are some of the abstractions that Joel Spolsky wrote about in his foundational article, "The Law of Leaky Abstractions." For instance, writing a file in VBA can be as little as one line of code. At the operating system level, though, the bits are not moved in a single operation. Rather, they are written to the destination file in chunks, based on the block size of the disk. In this case, the block size is 4,096 bytes (4K).
If you look closely, you can see that 147,456 bytes are stored in the JETF1B2.tmp file. Interestingly, the first byte stored is actually stored in the last byte of the fourth block of the file (Offset: 16,383, Length: 1). Then, bytes 0 through 16,384 are written to the file (i.e., the first four 4k blocks).
After that, the next byte stored is the last byte in the 36th and final block of the file (Offset: 147,455, Length: 1). Then bytes 16,385 through 147,456 are written to the file (though several blocks appear to have been skipped as there is a bigger-than-4K gap between Offsets 73,728 and 86,016).
My theory here is that the single-byte WriteFile operations are a way to force the disk to allocate several blocks at once (presumably, in the hopes that those blocks would be physically contiguous on the disk). But I digress.
The key takeaway here is the fact that this .tmp file exists at all.
Since there is no analogous temporary file created for the GROUP BY clause, I believe this likely explains the consistent performance difference between the two clauses.
Green: File Creation Overhead
The total time to write the .tmp file is only 0.012 seconds.
10:53:30.2340579 PM
-10:53:30.2218845 PM
---------------------
00:00:00.0121734 secondsThis alone does not seem to be enough to account for the 5 - 10% difference between the GROUP BY and SELECT DISTINCT clauses from my testing. This leads me to believe that the bulk of the difference–at least in this case–comes from some other overhead involved in creating the file.
If we look at the first WriteFile operation for the .tmp file and compare it to the previous WriteFile operation for the front-end .accdb database, we find a difference of 0.12 seconds.
10:53:30.2218845 PM
-10:53:30.1062746 PM
---------------------
00:00:00.1156099 secondsI filtered out other operations from these results to maximize the signal to noise ratio. So, the initial overhead required to write the file is likely less than 0.12 seconds. But, I do think it could be contributing as much–or more–to the overall speed difference between GROUP BY and DISTINCT.
Final Thoughts
The GROUP BY clause is faster than the SELECT DISTINCT clause (at least in these tests) because it does not require writing to a temporary file on disk.
While I would hesitate to say that "GROUP BY is faster than SELECT DISTINCT" in every situation, I do feel confident in saying that we can now account for the performance difference between these two clauses (at least in this scenario).
Also, as the difference seems to be based on whether a file is being saved to disk, I would expect the difference to be more pronounced on machines with slow spinning hard drives (5400 RPM) versus those with high-speed SSDs (such as my test rig).
In summary:
- GROUP BY is slightly faster than SELECT DISTINCT
- The slower the drive, the bigger the difference
- This may not be a universal rule (we tested simple cases only)
- The difference is hardly noticeable to users
- These tests were done on Access back-end database tables and may not hold for other types of data sources (e.g., SQL Server linked tables)
My final advice:
• All else being equal, use GROUP BY for new development.
• Don't sacrifice readability for the small performance gain.
• Don't change existing queries (it's not worth it).
External references
Special thanks to Colin Riddington (isladogs) for putting in the hard work of creating a test harness and then publishing it for the world.
Referenced articles
 Mike Wolfe
Mike Wolfe
Image by Maïlys Jans from Pixabay
UPDATE [2022-03-16]: Added section "Reproducing the Results" and posted additional screenshots to support my overall findings (h/t Karl Donaubauer).
UPDATE [2022-03-16]: Modified my "final advice" to include a note about not sacrificing readability for the slight performance gain (h/t Joakim Dalby).
UPDATE [2022-03-16]: Clarified that these results apply to Access tables, not necessarily other types of tables, such as linked SQL Server tables (h/t AHeyne).