VBA Dictionaries: AKA, Hash Tables
This is not an article about Amsterdam flea markets. Hash tables are the data structures upon which Dictionaries are built.


In yesterday's article, I wrote about collections in VBA and how they are (probably) implemented as "linked lists." Today, I'm going to talk about Dictionaries and their associated data structure, hash tables.
The Microsoft Scripting Runtime
I should start with the fact that Dictionary objects are not part of the standard VBA library. Rather, these objects come from the Microsoft Scripting Runtime. You can create dictionary objects using late binding or early binding.
'Late binding example
Dim MyDict As Object
Set MyDict = CreateObject("Scripting.Dictionary")
'Early binding example
Dim MyDict As Dictionary
Set MyDict = New DictionaryThe early binding method runs faster when initially creating the object, but you probably won't notice any difference. The bigger advantage to early binding is that you get IntelliSense support.
I avoid using early binding with most libraries for two reasons:
- The application won't even run on a machine where the library is missing. This complicates deployment.
- The program depends on each user having the same version of the library. This is most often a problem when integrating with other Office applications.
The Microsoft Scripting Runtime does not suffer from either of these drawbacks. The library has been present in every Windows operating system at least as far back as Windows XP. It is one of the few libraries that I install in almost all of my applications.
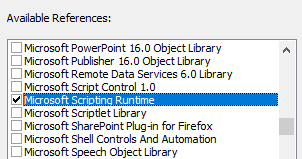
To include the library in your project, switch to the Visual Basic Editor (VBE), then go to Tools -> References... and scroll down until you see "Microsoft Scripting Runtime." Check the box to the left of the library name and click [OK].
Hash functions
At the beginning of this article, I wrote about how Dictionaries are implemented as hash tables. Before we can talk about hash tables, though, we need to talk briefly about hash functions.
Hash functions put the "fun" in function, at least if you're a math nerd like me. The idea behind a hash function is that you feed it some input and--through a series of mathematical operations--that input is transformed into a fixed number of bits, referred to as the hash.
The most important part of a hash function is that it must be repeatable (or "deterministic"). For a given input, the hash function must always produce the same output.
The second most important part of a hash function is that it should produce different outputs for different inputs. If we have a five-million character string, and we switch a single letter from a to b, then our hash function should produce two very different hash values.
This concept is known as collision avoidance. A hash function's ability to avoid hash collisions is what separates a good hash function from a great one. No hash function can avoid every collision. This is easily demonstrated via the pigeonhole principle.
Hash functions normally produce a fixed-size output, but they need to accept arbitrarily large inputs. If the fixed size of a hash function's output is one byte, then there are only 256 possible outputs. Since the function must accept more than 256 different inputs, there will be "collisions" where two different inputs result in the same output.
Hash tables
Now that we know what a hash function is, we can talk about how they are used in a hash table data structure. Here are the basic steps involved in adding items to a hash table. It's not meant to be a working implementation, only to demonstrate the concept. (In other words, don't show this to my Data Structures professor or you'll make him cry.):
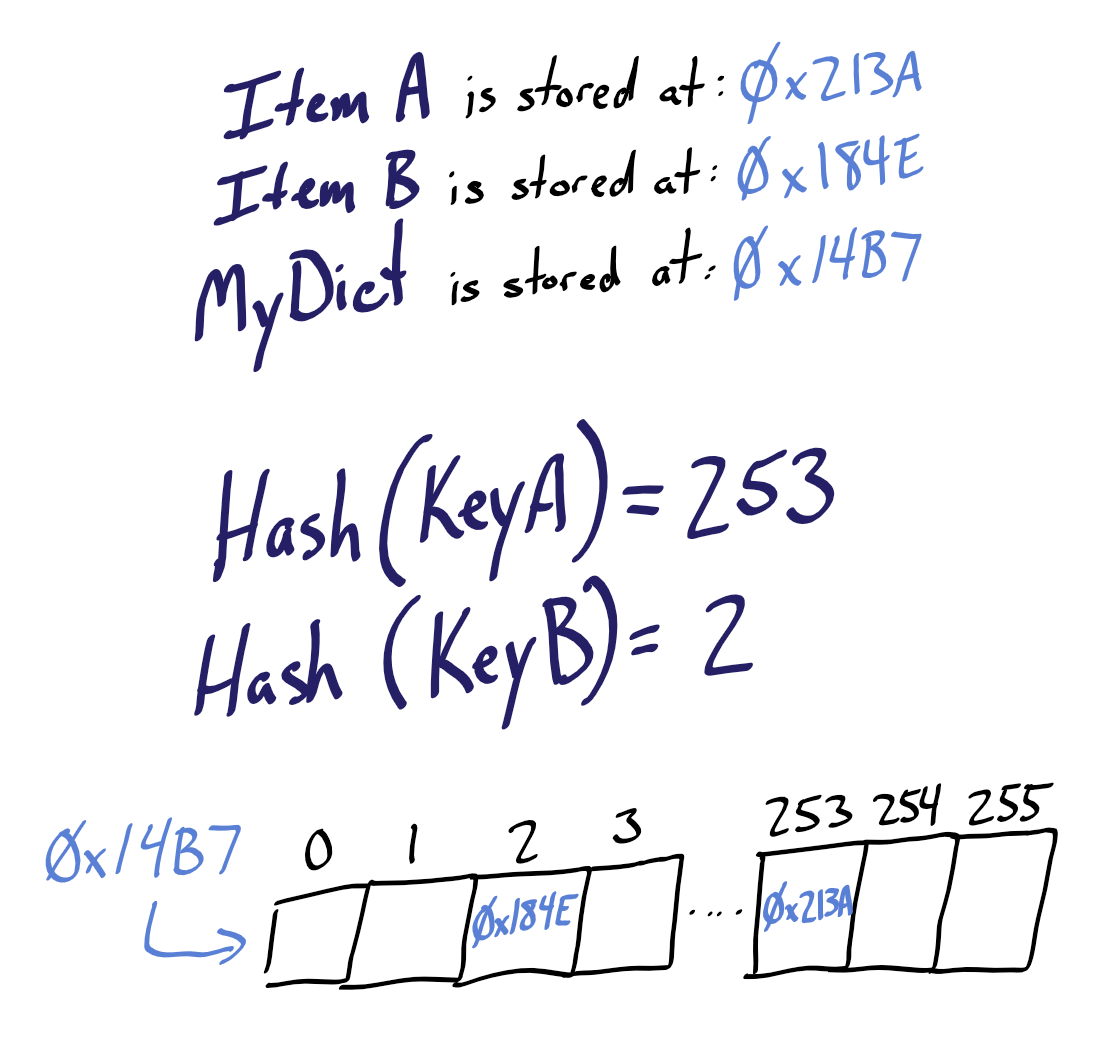
- Hash table declared: an array of 255 memory addresses is set aside in memory beginning at address
0x14b7. - ItemA, a 5,000-character string, is created and stored in memory at
0x213a. - ItemB, a 12-character string, is created and stored in memory at
0x184e. - The value ItemA is added to the hash table...
- ...we associate a key named KeyA with the value ItemA...
- ...KeyA is run through the hash function, producing a hash value of 253...
- ...the address of ItemA (
0x213a) is stored in block 253 of our memory address array. - ItemB is added to the hash table...
- ...we associate a key named KeyB with the value ItemB...
- ...KeyB is run through the hash function, producing a hash value of 2...
- ...the address of ItemB (
0x184e) is stored in block 2 of our memory address array.
This seems like a lot of work
What's the point of all this? That becomes obvious when it's time to retrieve our values.
We tell the hash table that we want the value associated with KeyA. KeyA is fed to the hash function, which returns the value 253. The hash table goes to the start of the memory address array, 0x14b7, then performs a memory offset operation to get to block 253 of our array. Because each block is a fixed size, this is a very fast operation.
Contrast this with our linked list example. If this were a linked list and we had to get to block 253, we would have to move one block at a time. This would be very slow.
The value of the key itself is all that we need to find its associated value. This is a very powerful feature of hash tables. It's one that I did not really understand when I was learning it.
The role of keys in linked lists vs. hash tables
With a linked list (e.g., a VBA collection), the value of the key will allow us to retrieve our item, but it's horribly inefficient compared to the hash table approach. With a linked list, the key is simply stored alongside its value in the list. To find a an item by the value of its key in a linked list, we have to "walk" the list checking each item's key to see if it matches the key we are seeking.
As you can see, keys serve very different roles in Collections and Dictionaries. Hash tables cannot function without a key to associate to an item. Keys serve no purpose with linked lists, though. They are included in the VBA Collection object only for convenience.
And now you know why the Key is a required parameter when adding items to a Dictionary but optional when adding items to a Collection.
What's in a name?
This data structure goes by two common names: hash table and associative array. If you've read this far, it should be clear now why each of those names is appropriate. I even italicized my usage of the word "associate" in the text above to draw attention to it in my explanations.
But why, then, did the Scripting Runtime library choose to call it a dictionary? Let's think about it. Imagine that the definition of a word is the Item in our example above. The Key, which is associated with that item, is the word being defined.
The hash table is the physical book where each page is some defined offset from the front cover. The hash function converts the key to a page number where the key and item (the word and its definition) can be found. This hash function produces dozens of collisions for each page number, so the words on any given page are further hashed and assigned a sequence within the page.
The analogy is not perfect. Hash functions do not generate ordered values. In fact, no hash function worth its salt would produce output in alphabetical order based on its input. Such a function would surely generate far too many collisions. But I think you get the idea.
Hand waviness
Please do not use this article as a basis for implementing hash tables in your next C project. In an effort to keep things as simple as possible, I did a lot of handwaving over the complexities of such an implementation. Heck, I never even broached the subject of how to handle collisions in the memory address array.
Of course, my intent was not to teach you how to implement hash tables. My goal was only to improve your understanding of the Dictionary object. I hope I've at least succeeded in that.