Finding Duplicate People by Date of Birth
Let's explore the GROUP BY syntax with an exercise in identifying duplicate records in a Person table.


In any database that stores records of people, there are bound to be duplicates.
Consider the following Person table. In addition to an Autonumber ID column, there are FirstName, LastName, and BornOn (i.e., date of birth) columns.
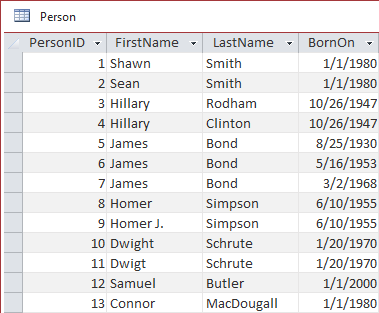
Duplicates can arise for a variety of reasons:
- Typos
- Alternate spellings
- Legal name changes (marriage, divorce, adoption, etc.)
- Cinemastasis*
* Cinemastasis: the frozen-in-time nature of long-running movie and TV franchises where the characters never age, especially as it contrasts with the passage of time in the real world (yes, I'm just making up words now)
Grouping By Birthdate
One way to identify duplicates in this set of data is to group them by birthdate. Let's start with a simple grouping query to find which birth dates are problematic:
SELECT BornOn, Count(*) As PersonCount
FROM Person
GROUP By BornOn
HAVING Count(*) > 1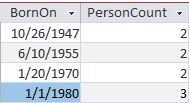
That's a little helpful, but there's not much useful information to go off of. Let's add some context to assist our poor end users.
Displaying Different Names
It would be much more helpful if we could put names to these dates so that we could resolve some of our problem data. It's not perfect, but one way to do that is just to show the Max and Min names for each date of birth:
SELECT BornOn, Count(*) As PersonCount
, MIN(FirstName) As MinFirst, MAX(FirstName) As MaxFirst
, MIN(LastName) As MinLast, MAX(LastName) As MaxLast
FROM Person
GROUP By BornOn
HAVING Count(*) > 1
Now we're getting somewhere. We can see that Hillary Clinton/Rodham might be the same person (legal name change). Homer Simpson has a middle initial of J. Dwight Schrute's name is prone to typos.
Wait, though. That last line shows that there are three people with the same birthdate, not just two. Connor/Shawn MacDougall/Smith are probably two completely different people. We need to reduce the noise a bit more.
Requiring Matching Names
Let's further refine the query to require that at least one pair of names matches, either the first names or the last names:
SELECT BornOn, Count(*) As PersonCount
, MIN(FirstName) As MinFirst, MAX(FirstName) As MaxFirst
, MIN(LastName) As MinLast, MAX(LastName) As MaxLast
FROM Person
GROUP By BornOn, FirstName
HAVING Count(*) > 1
UNION ALL
SELECT BornOn, Count(*) As PersonCount
, MIN(FirstName) As MinFirst, MAX(FirstName) As MaxFirst
, MIN(LastName) As MinLast, MAX(LastName) As MaxLast
FROM Person
GROUP By BornOn, LastName
HAVING Count(*) > 1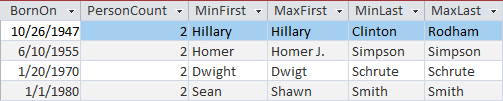
A quick little UNION query does the trick nicely. We now see that Sean/Shawn Smith is a likely duplicate.
It may be convenient to see all the potential mismatches in one query, but it would probably be easier to identify them if we split the UNION into separate queries. Let's try that next.
Separate Queries for First and Last Name Mismatches
Let's start by finding first name mismatches:
SELECT BornOn, Count(*) As PersonCount
, MIN(FirstName) As MinFirst, MAX(FirstName) As MaxFirst
, LastName
FROM Person
GROUP By BornOn, LastName
HAVING Count(*) > 1
Now let's do the same for last name mismatches:
SELECT BornOn, Count(*) As PersonCount
, FirstName
, MIN(LastName) As MinLast, MAX(LastName) As MaxLast
FROM Person
GROUP By BornOn, FirstName
HAVING Count(*) > 1
Multiple Queries Needed
The simple fact is that no single query will identify all of the potential duplicate Person entries. For example, none of our queries identified the duplicate James Bond entries in the list, since those records all had unique BornOn values.
Identifying this sort of invalid data is as much art as it is science. The downside to using multiple queries is all the other work involved in incorporating each additional data validity check query into your application.
But what if it was almost no work at all?
- Create a query named "Validity{QuerySuffix}"
- Add a row to the ValidityCheck table
Now we're getting somewhere.
Referenced articles
 Mike Wolfe
Mike Wolfe Mike Wolfe
Mike Wolfe Mike Wolfe
Mike Wolfe Mike Wolfe
Mike Wolfe
External references
 Contributors to Wikimedia projects
Contributors to Wikimedia projects
Image by modelnikosmith from Pixabay